My experiences from building microservices


Overview
Microservices is a complex topic, and sometimes dangerous too if you ask me. Mainly because it's easy to assume that microservice is KING and should be used everywhere once you start to work with them. This post won't be a detailed guide on how you write them, because to be honest, to get started with them can be extremely simple depending on your current architecture and organization. In it's essence, it's just another API or web app or some background job or something similar. It doesn't have to be "cutting edge" technology or anything like that to be a microservice. It's more important that the responsibility of the microservice is limited, rather than in which technology you build it. In more practical terms what this means is it might be more important that once you've built your microservice responsible for sending an SMS to a customer, you shall not add more functionality to it, for example. Let it send SMS. No more. This kind of "responsiblity" and where to draw the boundaries is very very hard, and by far matters more for your organizations agility than if it is written in NodeJS or C#.
This post will aim to give you some idea about what a microservice can be, and some patterns you might want to go for and some to avoid. In the end what we want to accomplish is a maintainable architecture that solves our business problems and can evolve alongside the rest of the world.
Agenda
- Why microservices?
- What's a microservice and where do they live?
- Make sure your infrastructure allows easy creation of new microservices
- Responsibility of a microservice is key
- Make sure the microservice has it's own lifecycle
- Patterns to avoid
- - Massive amount of API-API calls
- - Monolith-like looking code
- - Breaking changes
- - Never require to update 2+ microservices to achieve a piece of functionality
- Correlation logging is king
- Be ware of lots of (git) repos
- How big should a microservice be?
Why microservices?
Monoliths are good in that they're usually easy to test and get an overview of. You have one GUI where all happen through. Microservices are usually hard to test because they're spread across different teams and it's a mess to run all of them locally.
Still, a huge problem with a monolith is that it usually is slow to develop and that it usually doesn't scale well, and becomes very hard to maintain. It's not very flexible. Microservices on the other hand can provide very good agility to your organization, something that is very valuable today.
What's a microservice and where do they live?
When I started to work as a developer in 2012 I never heard the word microservice. I heard the word "system" and "SQL" a lot. You had a system and it had a database. That's it. This is a traditional monolith. Someone or some people started an API or a product, and over time every piece of functionality needed was added into this existing system. More functionality built into the system and more tables added to your database. This is how a monolith is built.
Depending on where you work, people can work for a whole lot of years without even knowing what the term microservice means or what it's good for. For me my journey into microservices was pretty strange. I actually started to build some API's and background job, and I was talking about microservices with a colleague when he said, "well, isn't it microservices that we're building now?" and I remember I was like "hm, no, or, well maybe - yes. I'm not sure, maybe we are, how do we know that this is a microservice?"
Here's a definition of a microservice from microservices.io:
Highly maintainable and testable
Loosely coupled
Independently deployable
Organized around business capabilities
Owned by a small team
Microservices lives where people decide to build them, and that's about it. There must be at least one person on the team that says "hey guys, why don't we build another API for this functionality?". A key aspect to get this to work is that the team must (by the organization) be allowed to build new applications, without hazzle. If it is your first time then be prepared for discussions.

Make sure your infrastructure allows easy creation of new microservices
To start off you might just build one microservice and that's it. But eventually one will become two, and two will become three. Before you realize it you have five microservices. So make sure you and your team has a "way" of building microservices. This is typically something that must evolve, so don't be too scared of it to start off with, just be prepared for it. Naturally you will come to a place where you really feel the need for consistent hosting, logging, monitoring etc. You don't need a container orchestration platform (Kubernetes for example) or Serverless hosting to start building microservices, absolutely not. But you will eventually most likely end up there, because it's nice to have a consistent way of hosting stuff.
So why must I (eventually, at least) make sure my infrastructure allows easy creation of new microservices? Because otherwise the time it takes to build each new microservice is too painful. Neither you nor the team or the product manager will accept it, becasue it's too cumbersome to create a new microservice. It must be relatively easy (say - less than two weeks) to create them, otherwise we won't bother.
Responsibility of a microservice is key
I think this is by far the hardest part in designing microservices.
Responsibility in terms of software means that no single piece of software (or system) shall have all functionality. If we read about Single-responsibility principle we find:
The single-responsibility principle (SRP) is a computer-programming principle that states that every class in a computer program should have responsibility over a single part of that program's functionality, which it should encapsulate. All of that module, class or function's services should be narrowly aligned with that responsibility
This is very applicable to microservices too.
At some point, when building an API for example, you must take the decision to put new functionality in another API, because otherwise the API will grow infinite, which is not very easy to maintain. This is how monoliths traditionally were built.
When talking about software, to group your software (or functionality) into closely-related systems is what gives them high cohesion. When talking about microservices this is essential. There is a reason why Shipping might be separate from Invoice. Both "responsibilities" or functionality change for different reasons, and might belong separate from each other. You want everything related to shipping inside the Shipping system, so that it has high cohesion. And you want functionality related to Invoice by itself, so it has high cohesion. But you don't want to mix them. I.e. in more practical terms - if you have a Shipping API with only 4 endpoints, it might be worth to create another API for Invoice, even if Shipping is currently "such a little API". Being small is not a good argument for adding more functionality in there for the sake of laziness. Microservices is an investment - you spend more time upfront (to create different microservices) for the sake of separated responsibilities and later on allowing your organization to be more flexible and deliver value to end customer more frequently.
Make sure the microservice has it's own lifecyle
All code starts with an idéa that you want to take to production. You want this process to be smooth.
You have a requirement, you implement it in your microservice, you ship it. Nothing else affected. Nothing. If you update the Shipping service you don't want to touch the Invoice service. You also want to be able to deploy the Shipping service independently of the Invoice service. You also don't want them to share databases, because at some point in time, another team will take over the Shipping service, and you want them to be able to do this without messing with other microservices. All this is what I call "have it's own lifecycle".
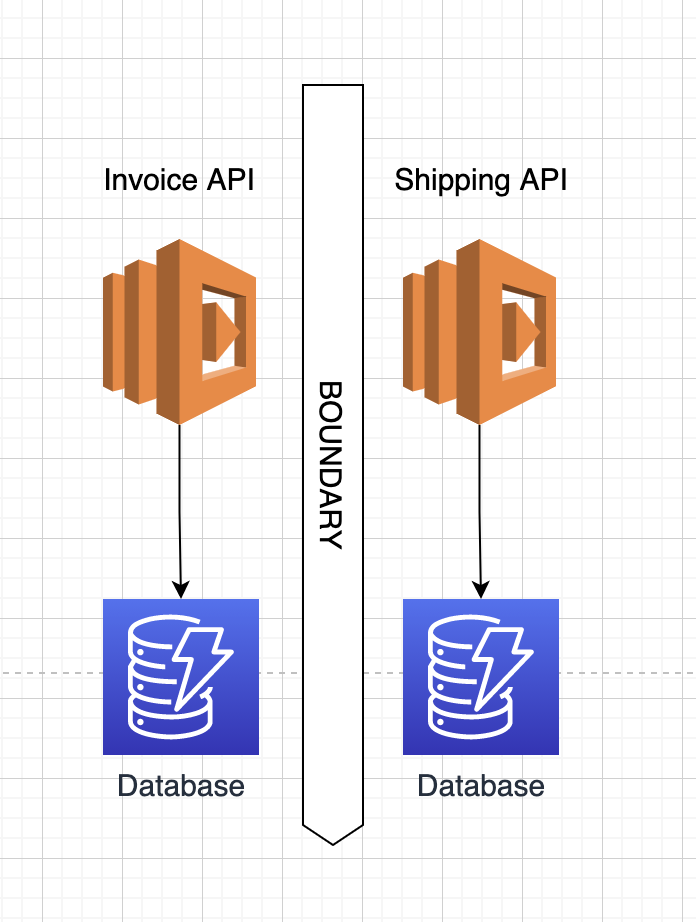
It's also worth to talk about "risk of failure" when building microservices. Essentially you want a small blast radius when something goes wrong. This is not only applicable to the functionality of each little microservice, but also in terms of deployment. If deployment fails (which it will sometimes) you want the Invoice to not impact Shipping. If you must deploy all your microservices with the press of one button, then you're doing it wrong (that's more like a distributed monolith). Versioning between systems will also be hard (impossible?) if you deploy them all at once. It's hard to know exactly in what order they will be up and running with the new version, and this is a problem unless all your services always are updated with 100% backward compatibility in both directions.
In real life some things become less used over time. Can be anything. The same is true with software. Microservices are built and later on removed in favor of something new (maybe a purchased system for example). Being able to then delete this old microservice is much easier if it has it's own database and such.
Patterns to avoid
Massive amount of API-API calls
I think it is very easy to fall into this trap. Jimmy Bogard explains it well why you will want to not have your microservice architecture be dependent on API's being up all of the time (like 99,99% SLA). This is not a good approach. My general take on this is that you will have to drop consistency, copy data across your microservices and accept eventual consistency for it to scale well.
A colleague of mine told me something very simple I haven't really thought about: If you have 5 API's in the chain with an SLA of 95% per API that's effectively 77% SLA (0,95*0,95*0,95*0,95*0,95). Who would ever want a 77% SLA?
Breaking changes
Any two microservices communication with each other will inherently have a contract between each other. If this contract is broken then that's what we call "breaking change". Avoid having to do breaking changes, especially between teams. This is true both for event-driven architecture and synchronous API to API architecture. Instead try to do backward-compatible changes and then later on cleanup the "obsolete" stuff when all teams have migrated to the new versions.
For example in a REST API - add a new property to the response of one endpoint instead of rename a property. The rename is breaking, whereas the addition of a new property is not. When all other teams communication with your REST API is using the new property you can safely delete the old property. It does require a bit of extra work, but the benefit is that no change is breaking, which is a good thing.
Never require to update 2+ microservices to achieve a piece of functionality
Creating new apps or API's (microservices) because you can and because it's simple doesn't mean its right. The same time you realize that "oh fuck, I must update all these 3 microservices" in order to add one new business feature, you've built a distributed monolith. This whole idea very much connects back to the responsiblity we talked about earlier and why it's important.
Correlation logging is king
One of many ways to know if a system is healthy is logging. In yesterdays systems we logged stuff raw into a SQL table or maybe a text file. Nowadays we use structured logging, and with structured logging it's very pleasant to introduce "correlation logging". One of the challenges with microservices is that they are by definition a "living creature" by themselves. So if one microservice says something, you must know the other microservices reaction. And this is where correlation id comes into play. I shall say this assumes that you're ingesting logs from multiple microservices into the same database (ElasticSearch for example). Practically speaking it's just about sending your logs from each of your microservice into the same database in some way - and keep the same structure for each of the logs.
Correlation logging means to log something that allows me to correlate a happening in system X with the response from system Y. Like when Alice calls Bob, you would ideally want to know what Bob did in order to answer. If Alice logs a special id called CorrelationId, and also sends it to Bob, and Bob also logs this special CorrelationId, then you can track the behaviour across your "things" or microservices. This is why Correlation logging is king. It bridges the gap between microservices and allows you to actually see what is happening between them.
I think the actual name here - CorrelationId or not - might be a bit different in different organizations and teams. For example, the w3c is working on a standard for HTTP for this. Altough different names, the goal is the same, to send/log something across systems (microservices) to correlate behaviour.
Be ware of lots of (git) repos
Once you have multiple microservices it must be easy to work with them. Altough I haven't tried it myself, i'm leaning towards a monorepo structure where you only have one single repo for all your code bases. The other option is to have one repo per microservice (which is what I have now, but i'm starting to dislike). It's just too cumbersome to fetch 10 different repos.
How big should a microservice be?
tldr; It is very hard to know and no real way to "measure" it.
This is a hard to answer for the same reason there will most likely never be an easy way to "measure" whether your system or app is a "microservice" or not. I think this short video (8 min) of Sam Newman explains it well:
Summary
My take so far on microservices is that the battle between monoliths and microservices is less important, but responsibility is the important part. I do not believe that monoliths are dead, but I do however believe that generally speaking your organization will be much more flexible with small services with a clear responsibility.
I also see a great benefit with microservices that they are (in case needed) much easier to move between different teams in the organization. Organizations will inevitably change, so I think it's very valuable if our architecture allows for that.
Last but not least - from my experience the by far hardest part is to make each microservice have it's own responsibility, and not let that responsibility pollute other microservices. It's hard to draw these lines clearly. If you think about it in other terms - say a football coach and an ice hockey coach, you expect to always go to the football coach for advice for that sport. If you one day must go to your ice hockey coach to get recommendations for a new pair of football shoes things start to be pretty unexpected. Responsibilites and knowledge starts to blur and become a mess. While easy to relate to, I think it's a fair anology of how you can relate to computer systems (microservices), and also a good point on why responsiblity is very important to keep microservices intact.