A different approach to log levels


Logger.Information("Overview");
Ever seen a system log quite a lot of information yet you have no idea how to interpret it? Ever seen errors being produced every single day yet no one really bothers to read them? Or warnings being 'normal' in your application? During our years as software developers, we've learnt to use log levels based on where in the code we do the logging, which is wrong. In C# for example, people tend to log errors in catch statement because an exception is naturally an error, but this often Isn't very valuable.
Take a look at the below picture for example:
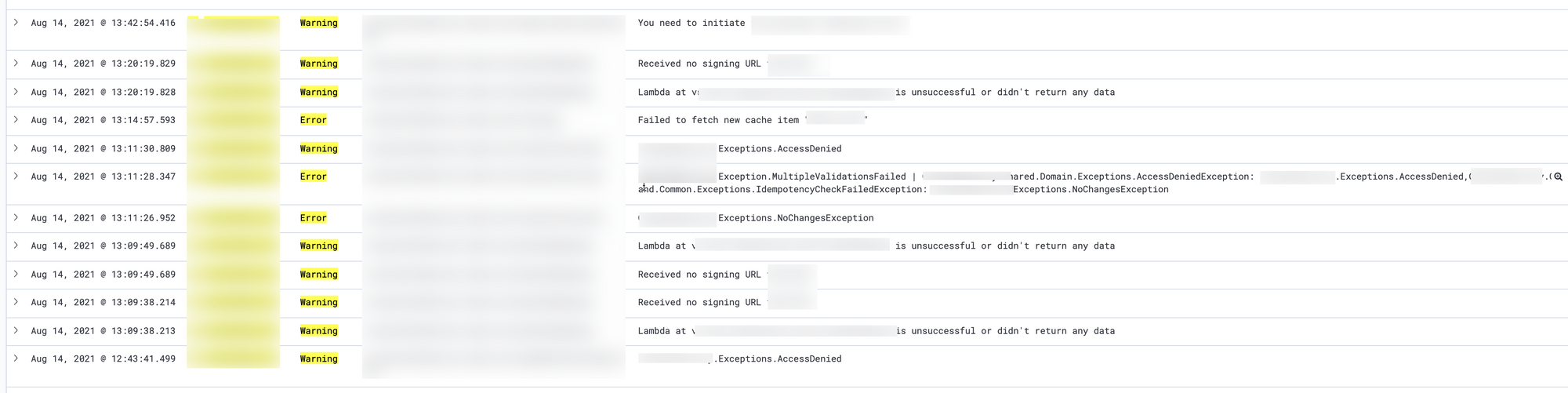
This is an example of logs shown in Kibana on a project where I've worked at. It's not special in any way, and this is some of our daily logs. The problem with the above logs are not that they exist per see, but that no one bothers to read them. It begs the question, why does no one bother to read them? Should we fix them? Is the application broken? What do the customers experience?
It's crucial to understand the logs of your system, because your logs is one way to measure the health of the system. In this post I'll give you another way of deciding what log levels to use. The primary reason for doing this and the goal we want to reach is to understand how our system behaves, with logging that is more clear and done with intention, rather than accident. I also find this surprinsgly easy to start doing, which is a very nice bonus. This idea of the log levels I'll describe is by no means invented by me, but instead I'm heavily inspired by this article: Logging levels: the wrong abstraction.
Logger.Information("The different log levels");
There's a number of different established log levels in the industry if you will. Here are the most common ones:
- Fatal/Critical
- Error
- Warning
- Information
- Debug
- Trace
Are all of them useful in your system? Most systems I've worked with have been using a subset of these, for example Information, Warning, Error and Fatal. What your team uses if of course up to you. It's far better to use a subset of the log levels but using them with a clear and outspoken convention in the team, rather than using all of them just for the sake of... nothing? What matters is that the log levels used gives your team valuable information.
Logger.Error("Exception occured but we have no idea what to do about it");
I think it's fair to say that most developers reading the above code block would say it looks good. To log an error seems reasonable for most people here. Why do the above log statement feel so right when reading the code, but also could be useless? I've seen so many try/catch statements that just logs an error because if you catch an exception it must be... an error... right? I would say this is very often a bad thing. And this is also the traditional way of logging I'd say. No one really questions this code when reviewing a pull request.
Logger.Information("Another definition of log levels");
What if I instead told you that your choice of log level shall be determined by how much attention should be given how quickly if that log statement is executed.
So if we decide on using these log levels and the following definition:
- Fatal - let the team know immediately. Something must be done manually to fix this, and what to be done should be included in the message.
- Error - Important to investigate, but can wait till tomorrow.
- Warning - It will be beneficial if someone investigates these, but can be done during the week.
- Information - Useful business-related information like "order purchased" rather than "web request made".
- Debug - Useful information about the behaviour of your system such as "web request made" or "database connection established".
With this definition and a new way to interpret the log levels, the below log statement is maybe more suitable for our system since network calls can often fail, but that doesn't mean we must investigate them today, or even do anything about it:
But what if we had the following code?
This is just an example, but a reasonable one. The important bits here are that if this fails, we know the system is now in a state where it cannot recover by itself, but needs manual intervention. In this case Fatal makes perfect sense - something happened that we must take an action on straight away.
Logger.Fatal("This must trigger an alarm to notify us that something bad has happened");
Now that you have a definition of your logging levels, and you know that whenever someones logs fatal in your code, you must be aware of it as soon as possible. There are different way to accomplish this and it depends on what tech stack you use. I've been using ElasticSearch for logs and ElasticSearch has a feature called Watcher that let's you define a custom threshold (for example any fatal log) and connect that Watcher to a Slack channel. In this way the team will get a Slack notification whenever something happens that we must be aware of. Other tech stacks have their own way of accomplishing the same thing, for example AWS CloudWatch also has an Alarm capability.
Logger.Information("This is nice");
If you've come this far I think you're doing very well. Everyone in the team understands the importance of log levels and can also interpret the importance of information that your system logs.
Logger.Information("But 200 warnings must be more critical than 1 error");
The critical reader now is most likely thinking:
Wait a second, 300 warnings within a 5 minutes period is more important to investigate than 1 single error during the last hour, so this definition doesn't work
And of course that's true. The definition above isn't 100% bulletproof, and I'd even argue that there is no definition of log levels themself that can cover every single case, but the definition I've mentioned above is way better than having no definition at all. When everything comes around, we will need more intelligent alarms to help us.
Logger.Information("More intelligent alarms");
There is something called anomaly detection, which - as the name implies - detects anomalies in your data. This can help you still get alarms for anomaly cases such as the one mentioned above with 200 warnings during a short period if you usually have 100 warnings a day. ElasticSearch already has it implemented for example:
I'm sure as the years pass by, it'll soon be mainstream to have Watchers/Alarms that uses AI/ML for anomaly detection. Even though it already exists today, in my experience it's not really that common for everyone to use. Same story with all tech, it takes a few years to pass the Hype Cycle.
Logger.Information("Summary");
As humans we are very good at adapting ourselfes to different environments, and it usually only takes a few weeks to "learn to ignore errors because they doesn't mean anything anyway". Don't fall into this trap.
The most important part is that your team has the same view on log levels and that they mean the same thing for everyone. Therefore it's worth to set a definition for your team of what your log levels actually mean. In order to improve our systems we must watch the logs coming out of it, and if these logs have no pre-defined meaning they are hard to interpret and will naturally be ignored by developers.